 Oliver Nelson
Oliver Nelson
Why Migrate from Btrieve to PostgreSQL and other Relational Databases?
Introduction Many independent software vendors (ISV) and corporate users still rely on applications that use a category of database collective called...



Migrate and run DataFlex applications with Oracle, MS SQL Server, PostgreSQL, MySQL & MariaDB.

Stuck in Crystal XI? Upgrade and use the latest versions of Crystal Reports with DataFlex applications.

Seamlessly convert from Btrieve transactional database to PostgreSQL, Oracle, and MS SQL Server.

Quickly build multi-protocol web services with the same API. Supports JSON-RPC, REST, SOAP, Thrift, and gRPC.




DataFlex developers looking to switch to Unicode must make extensive changes to their code base. To reduce conversion time, many developers have asked us if our drivers support the ability to use ANSI and Unicode character sets in the same application. While this could save time in code conversion, we advise against it mainly because mixing Unicode and ANSI can lead to data corruption issues.
This blog will delve deeper into why mixing character sets is ill-advised and why we recommend using Unicode character sets exclusively.
First, let's define what we mean by a “mixed environment.” This has multiple definitions, each with their unique challenges:
Using a Unicode Edition of our driver with DF >= 20.0 against an ANSI database.
Using a Unicode Edition of our driver with DF >= 20.0 against an ANSI database along with the Classic Edition of our driver against DF <= 19.1.
Using a Unicode Edition of our driver with DF >= 20.0 against a partial Unicode/ANSI database.
Using a Unicode Edition of our driver with DF >= 20.0 against a partial Unicode/ANSI database along with the Classic Edition of our driver against DF <= 19.1.
Using the Classic Edition of our driver with DF >= 20.0 against an ANSI database.
Using the Classic Edition of our driver with DF >= 20.0 against an ANSI database along with the Classic Edition of our driver against DF <= 19.1.
Using the Classic Edition of our driver with DF >= 20.0 against a partial Unicode/ANSI database.
Using the Classic Edition of our driver with DF >= 20.0 against a partial Unicode/ANSI database along with the Classic Edition of our driver against DF <= 19.1.
As you can imagine, based on just the list above, what each person considers a “mixed environment” can be very different. The most common scenarios we’ve been asked about are #2, #4, and #6.
If you were to “try out” each scenario with a simple test, you’d find that things generally work. But as you take on more complex tests of real-world scenarios, things will begin to fall apart. In general, three problems arise:
The first problem is that our Classic Edition drivers - which work with versions of DataFlex back to the mid-90s - use techniques for marshaling data that are incompatible with versions of DataFlex greater than 19.1. To be compatible with scenarios #5-8 described above would require adding another interface for using any of the custom commands defined in mertech.inc for versions of DataFlex >= 20.0. Although this is possible to do (and something we considered), it just doesn’t make sense when considering the rest of the problems.
The second problem is that there is no practical way to use a Unicode application environment against a non-Unicode database. This is where the logical fallacy comes into play: You can definitely “convert” Unicode data to ANSI. But this conversion is lossy: characters that can’t be represented in the desired ANSI codepage are replaced by placeholder characters. As we’ll see later on, this practice can cause all kinds of trouble. Conversely, you can “convert” ANSI data to Unicode, but the conversion can give slightly different results depending on how it is done (differing grapheme clusters), and it depends on the ANSI codepage in which the data was written. This means that the “conversion” to Unicode isn’t universally deterministic. A non-deterministic and lossy conversion means that unexpected results within your application are not only possible but also probable.
Additionally, to make all of this work correctly, various settings need to be adjusted just right, depending on the database being used. Things like ANSI codepage, ANSI collation, Unicode collation, Windows regional settings, Windows system locale for non-Unicode programs, and others must be correct so that the mixed environment does what you think it should do. If anything is set wrong or you don’t plan for every possible scenario, you can easily corrupt data in your tables.
When mixing Unicode and non-Unicode columns, sometimes - especially with embedded SQL - an unexpected performance penalty can be placed on your query. For instance, if you have a non-Unicode column in your table, but you’ve changed all of your queries to use “N“ prefixed strings to indicate that they’re Unicode strings, a query that would normally perform an index seek operation (which is very fast) can instead perform an index scan operation (similar to a table scan operation which is very slow). In many cases, an implicit conversion from Unicode to non-Unicode (or vice versa) needs to be done, but because this is done implicitly, you may not realize that you’ve unintentionally slowed down some operations in your application tremendously.
Here is an article that goes over more details. Even if you’ve limited what can be put into a column to just a subset of characters that overlap between Unicode and non-Unicode, there is still the possibility of having problems.
In all of these examples, we’ll look at the most common scenario of attempting to use DataFlex 2023 against a non-Unicode MS SQL Server database. We are using a Unicode driver and accessing this database from a non-Unicode version of DataFlex using a non-Unicode driver.
Often, it’s pointed out that the only thing that’s lost when you use a Unicode application against a non-Unicode database are the Unicode characters that can’t be represented in an ANSI codepage. Although that is true, the extent of loss is based on how Unicode is used, especially on the web. For instance:
Emoji – Although this normally comes up in notes columns and similar, emoji being lost can be critical, especially as it relates to legal proceedings. For instance, a recent US court case ruled that a thumbs-up emoji (👍) constituted acceptance of a contract.
Mathematical Numerical Symbols – Unicode contains a block of characters consisting of bold, italicized, serif, and sans-serif Latin letters and combinations of the proceeding styles (bold-italicized-sans-serif). Here is an example: “𝙃𝙚𝙡𝙡𝙤 𝙩𝙚𝙭𝙩 𝙨𝙩𝙧𝙞𝙣𝙜 𝙢𝙮 𝙤𝙡𝙙 𝙛𝙧𝙞𝙚𝙣𝙙”.
Young people often use these symbols to force the stylizing of text. It is easily readable, and most Unicode collations sort this data correctly, but it is mostly lost in conversions to ANSI codepages. If you look at the binary or hexadecimal representation of the above example text, you’ll see that this isn’t text that has a bold style set on it.
Stylized Characters – There is another block of Unicode for Latin characters with a “flare.” An example using the same text as above: “🅗🅔🅛🅛🅞 🅣🅔🅧🅣 🅢🅣🅡🅘🅝🅖 🅜🅨 🅞🅛🅓 🅕🅡🅘🅔🅝🅓”. This stylized text can get really wild. For instance, here are the same English words stylized using the Bamum Unicode block: “𖦙𖠢ꛚꛚ𖥕 𖢧𖠢𖧦𖢧 𖨚𖢧𖦪𖥣ꛘꛪ 𖢑ꚲ 𖥕ꛚ𖦧 𖨨𖦪𖥣𖠢ꛘ𖦧”. Often, this stylized text is used as a form of self-expression.
Foreign Language Characters – Although you can fit many Latin language characters into one of the common ANSI code pages, not all Latin characters fit. If you’re dealing with the need to record any foreign language such as Greek, Russian, or even German, you’ll find that these recognizable characters get lost when converted to an ANSI codepage.
Punctuation – This document has used punctuation that falls outside most standard ANSI codepages. Things like directional quote characters, emdash vs. horizontal bar, double prime (used in GPS coordinates), and triple prime (used in mathematical formulae and Slavic transliteration) fall outside nearly all ANSI codepages. These will be lost.
Symbology – Unicode contains electrical, mechanical, and safety symbology, currency, and even denomination symbols.
Sometimes, the argument is made that these additional items are rarely used. However, once a system supports the use of this type of expression and abbreviation, we have to assume that it is used regularly. Many of the categories listed above are in the most commonly used list of Unicode characters, not the esoteric “dusty corners.”
As an example, we’ll use stylized characters, which show fine in a Unicode application but cannot be represented in ANSI.
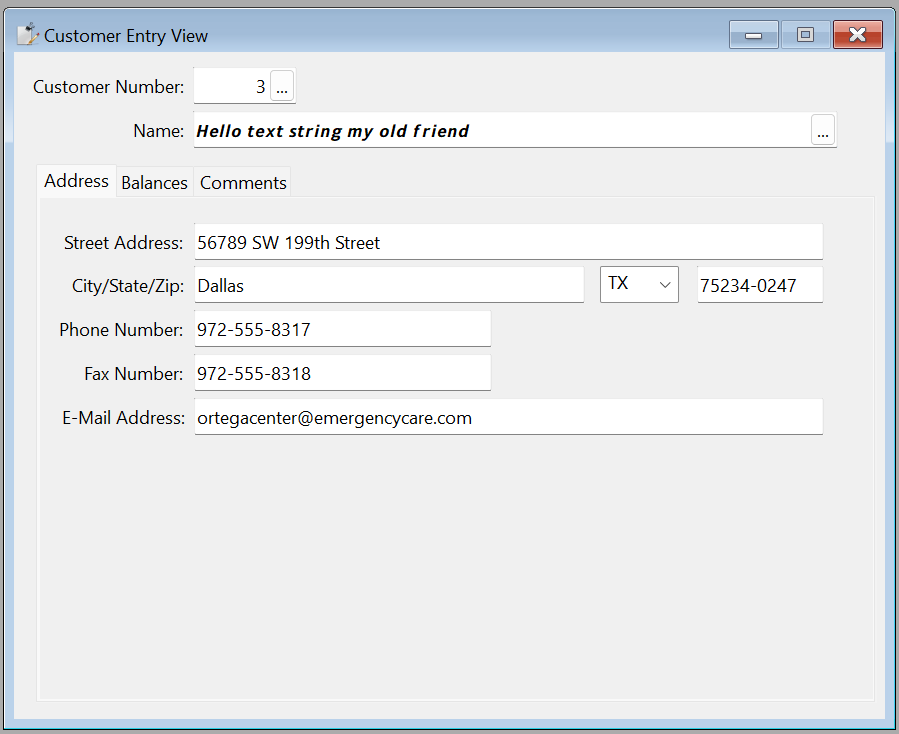
A text string is being put into the DF 2023 Order Entry example in this example. In this case, we’re using a Unicode driver against SQL Server 2022, and the Name column is varchar. When the text “𝙃𝙚𝙡𝙡𝙤 𝙩𝙚𝙭𝙩 𝙨𝙩𝙧𝙞𝙣𝙜 𝙢𝙮 𝙤𝙡𝙙 𝙛𝙧𝙞𝙚𝙣𝙙” is entered it shows correctly. If the Name column were a varchar type, this string would also be stored correctly. It certainly looks like it will be stored just fine from the screenshot above. But when this record is saved, the conversion is lossy. When we pull this same record up, we see this:
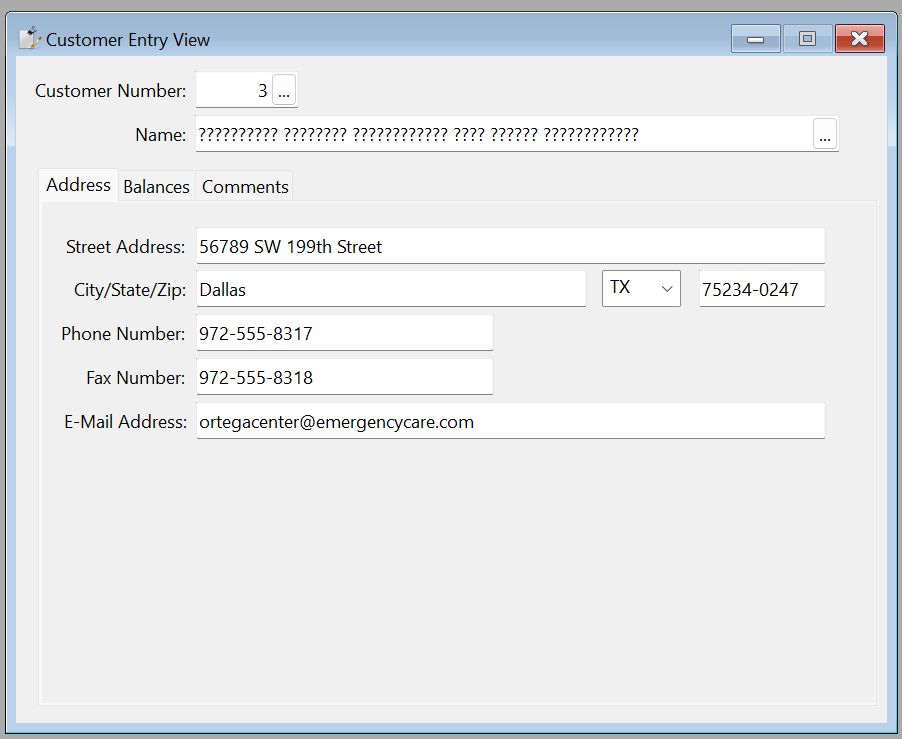
The record would look the same in DF19.1 using a non-Unicode driver because the data was actually lost and replaced by question mark characters. In standard Unicode implementations, This is something that uses some “filler” character when a lossy conversion takes place.
Probably the most common way in which you’ll see data corruption when mixing Unicode and non-Unicode data involves where users get their data. Unicode has multiple ways in which a single character can be represented. This is often referred to as “composed” (NFC) or “decomposed” (NFD) characters. You may also hear a “decomposed” character called a grapheme cluster. The basic idea here is if you have a character like “à” it can be represented in multiple ways. A character in Unicode U+00E0 represents “LATIN SMALL LETTER A WITH GRAVE character.” This representation uses 2 bytes of space. Then there is a decomposed version of the same character: U+0061 + U+0300, representing “LATIN SMALL LETTER A” + “COMBINING GRAVE ACCENT”. This representation uses 3 bytes of space. Both are valid UTF-8 byte sequences. Different applications can choose to use one or the other. For instance, an application may allow you to enter the letter “a” and then add the grave accent (or vice versa) and will store this as either of the above options. On the web, it’s common to come across both forms of Unicode, and your application should handle both forms well.
When decomposed (NFD), Unicode is used against a non-Unicode database, however, bad things happen. Not only does it cause inconsistency within the Unicode application (the storage of NFC and NFD formatted data), it causes a different inconsistency with non-Unicode applications. For instance, if this string is entered into a DF2023 application with a Unicode driver and the name column is correctly a Unicode-capable varchar (in the case of MS SQL Server), everything works as expected:
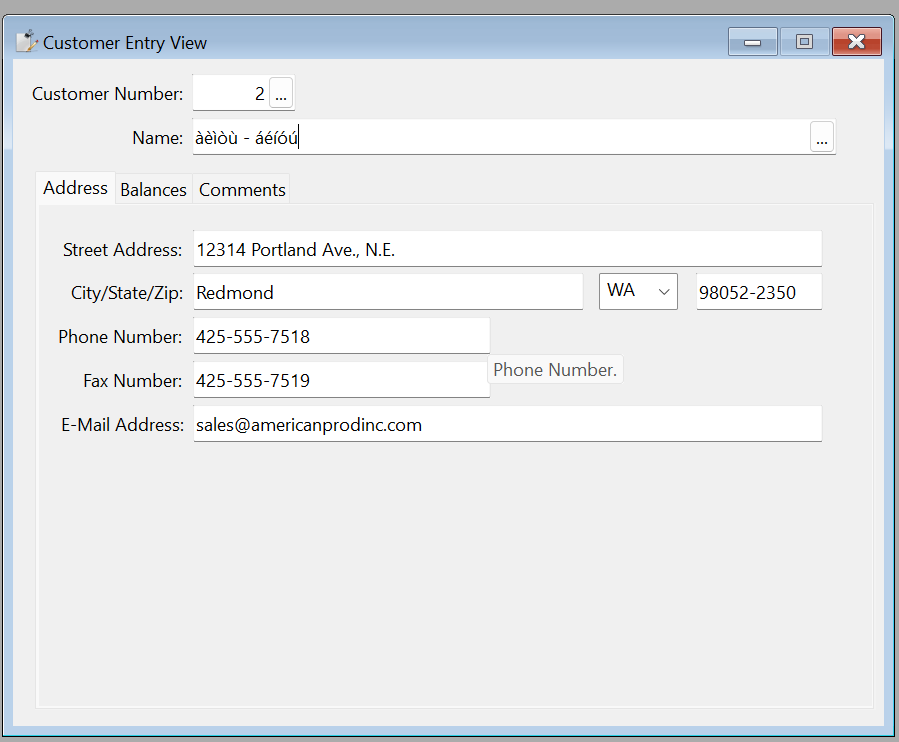
But, if that column is left as a varchar column, one of two possibilities exists. If the data is entered in composed NFC form, then the data will be converted and saved correctly. If the data is entered in NFD form, then when that row is saved and pulled back up, it will look like this:
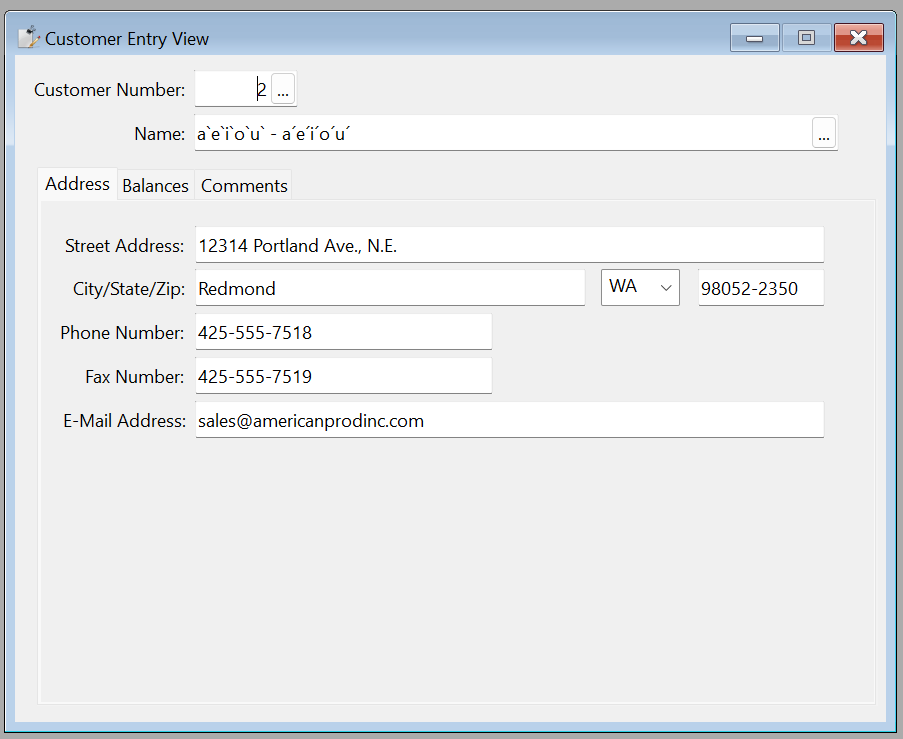
The decomposition has moved the grave accent from being over the character. You might look at this and think to yourself that it is still mostly okay, but let's pull up this same record now from an older version of the order entry application. We’ll use the DF 19.1 Order Entry:
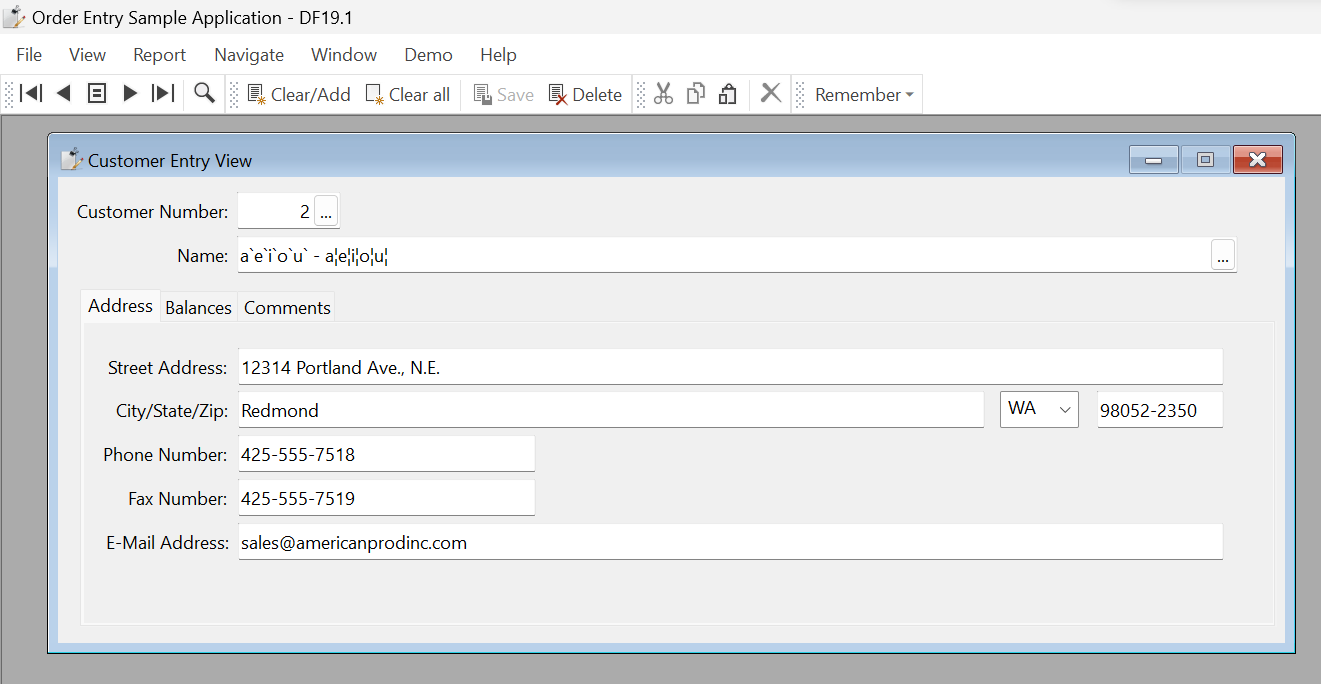
Notice that the grave accents (the backwards-facing accents), although in the wrong place, are still the correct character. However, the acute accents are replaced with a broken bar symbol (which is separate from what programmers would call a “pipe” symbol).
All of this depends on how a user entered the data, what type of keyboard they used, and where the data was entered, making it very difficult to track down the source of corruption. For instance, a webpage from some browsers can use NFD in some cases and NFC in other cases.
After going through the above section, “Data Corruption Due to Unexpected User Behavior”, you’ll see that it is also an example of non-deterministic data conversion. Depending on how the data is represented, Unicode engines will choose different down-conversions that can sometimes be correct, and others can be lossy. This isn’t a function of Mertech’s driver versus DAW’s driver. Instead, it’s related to the underlying Unicode conversion functions provided by the operating system and included in all drivers' ICU libraries.
This isn’t an issue when the column itself is Unicode because the equality engines built into the database servers can determine that different character representations can be treated with the same weighting.
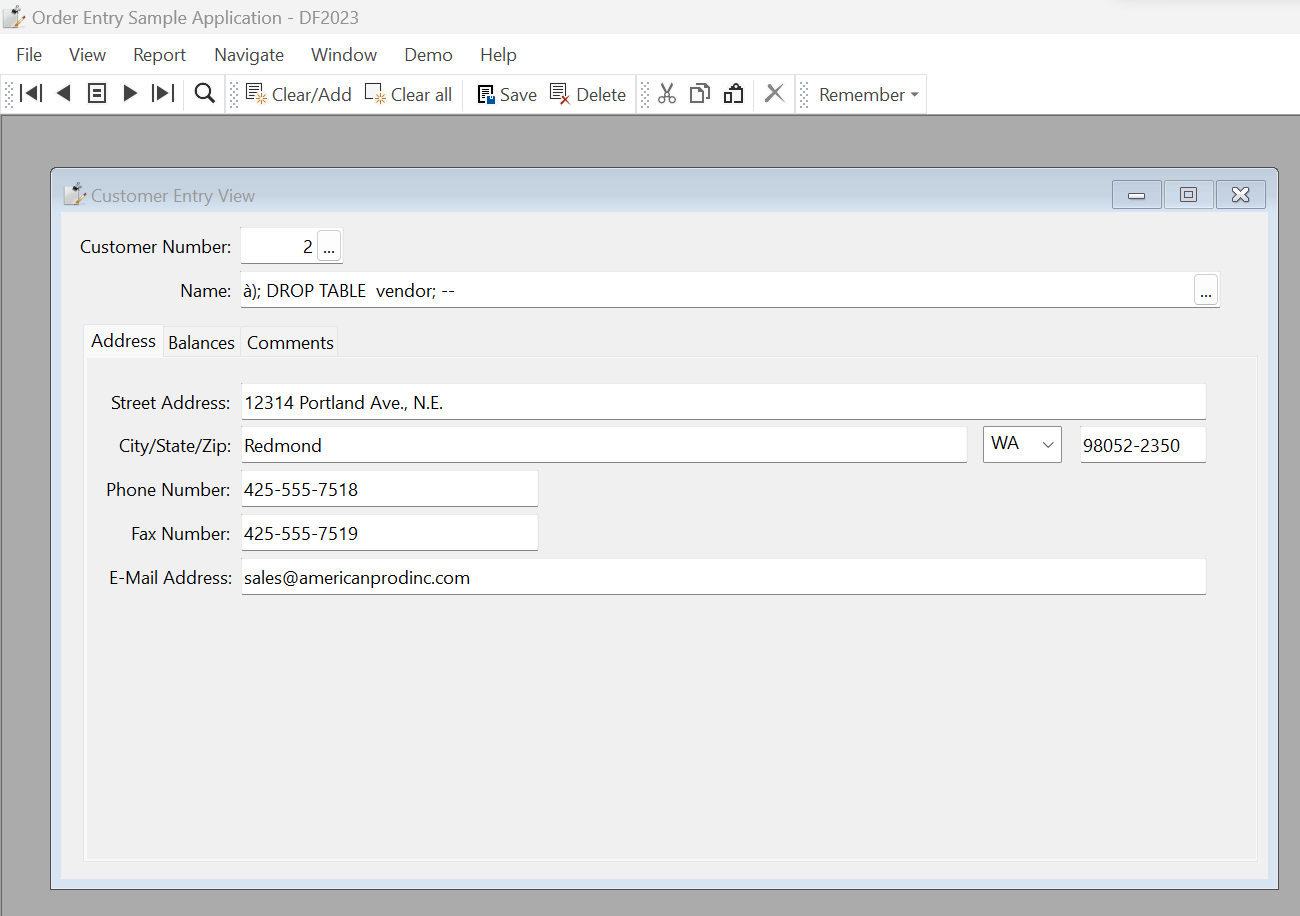
Let’s take a non-Unicode driver with the Unicode version of DataFlex and a non-unicode database. When this is paired with decomposed Unicode grave accents, even “escaped” user input can cause an SQL injection attack. This relates to how the DataFlex runtime deals with a non-Unicode capable driver when sending decomposed Unicode. In this case, the runtime converts the grave accent to a single quote character. This is a “magical character” in SQL and is one of the primary ways SQL injection attacks are executed. By setting a column to something like à); DROP TABLE vendor; -- but with the “à” character decomposed (NFD), the runtime passes the driver the string a'); DROP TABLE vendor; -- which sets up a SQL Injection attack possibility.
This risk still exists even if the data coming into your application is escaped. So, as an example, let’s paste this specially crafted string into the DataFlex 2023 Order Entry application, which is set up to use the v6.3.0.15 MSSQLDRV driver against an ANSI customer table. We’ll even add a function into the code to escape the input in this Windows app. Here is what it looks like when pasted in:
Normally, there would be NO risk to this string whatsoever. But because of this mixed environment, this string ends up being saved into the table as this:
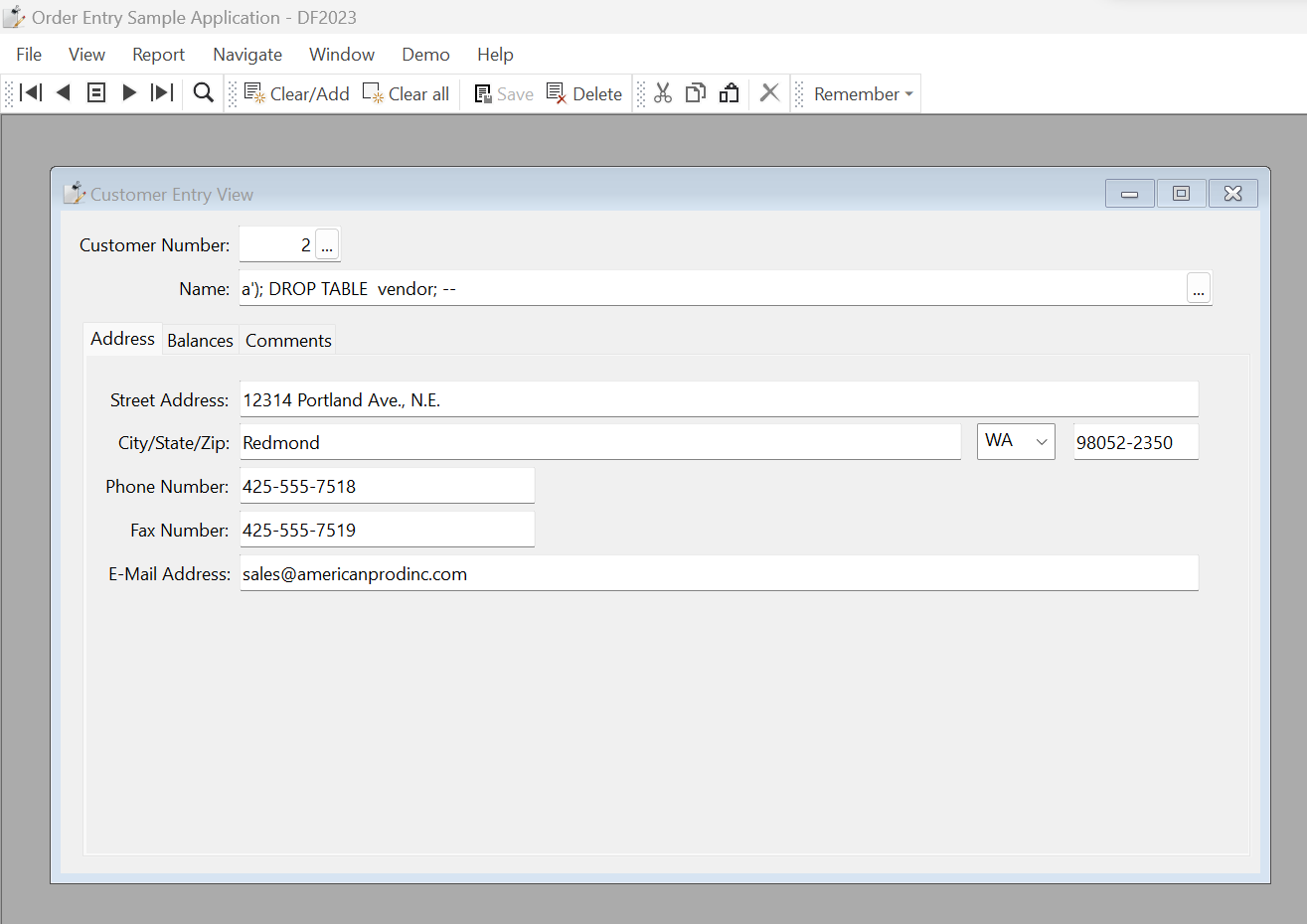
Notice that instead of “à” we have “a'“ saved into our record. Now, if that name is used later in an older application that has embedded SQL based on string concatenation rather than parameterized queries, we could easily end up deleting our vendors table:
Procedure OnClick
Handle hDBC
Handle hStmt
String sStmt
Clear customer
Move 2 to customer.customer_number
Find eq customer by Index.1
Get SQLConnect of hoSQLMngr 'MSSQLDRV' CS_CONNECT to hDBC
Move ("INSERT INTO Salesperson values ('AA','Some Customer', '" + customer.name + ".jpg')") to sStmt
Get SQLOpen of hDBC to hStmt
Send SQLExecDirect of hStmt sStmt
Send SQLClose of hStmt
Send Info_Box 'Done ...'
End_Procedure
This code above could now generate this SQL statement:
INSERT INTO Salesperson values ('AA','Some Customer', 'a'); DROP TABLE vendor; -- .jpg')Although a record is inserted as intended, because of the way the runtime down-converted the “à” character, our statement has “broken out” of its string and can execute arbitrary SQL, which, in this case, drops the vendor table. Although modern applications tend to use parameterized queries, one of the main reasons developers want to use “mixed” environments is to use older applications that are likely still using string concatenation. Although this risk can be mitigated via various techniques and even a fix from DAW, it illustrates well the complexities and inherent risks of using a mixed environment.
Since releasing our first Unicode drivers, Mertech has emphatically stated that it doesn’t support environments that mix Unicode and non-Unicode. Although there are many situations where it is just fine to have non-Unicode columns in an otherwise Unicode-aware application, doing this across your entire database and application can bring with it performance penalties, data loss, data corruption, and even security risks.
Moving an application to Unicode is not a small undertaking. Although building a new application in Unicode can be easy (and in fact, in many cases, is easier than it was to build a non-Unicode application), converting an application requires thoughtful planning, testing, and understanding of the issues inherent in using an entirely different way of representing characters. Additionally, this means that companies should think carefully about when and how they choose to update from a non-Unicode version of DataFlex to a Unicode version.
For these reasons, Mertech continues to support and improve the Classic Edition of our drivers, which are intended to be used alongside non-Unicode versions of DataFlex. We also simultaneously support an entirely new series of Unicode-based drivers to give you more options and flexibility in your business.

Introduction Many independent software vendors (ISV) and corporate users still rely on applications that use a category of database collective called...

COBOL applications are the foundation of numerous essential business functions, especially within the banking, insurance, and government sectors....

Imagine breaking free from the constraints of old, monolithic systems and embracing the agility and innovation of cloud-based solutions.